TLDR
Key Metrics:
In 2024, the widespread adoption of AI will become a reality. Previously, many companies encountered a major obstacle due to the absence of scalable evaluation methods for large language models (LLMs). They were unsure if their LLM-powered prototypes were safe enough to release to their customers.
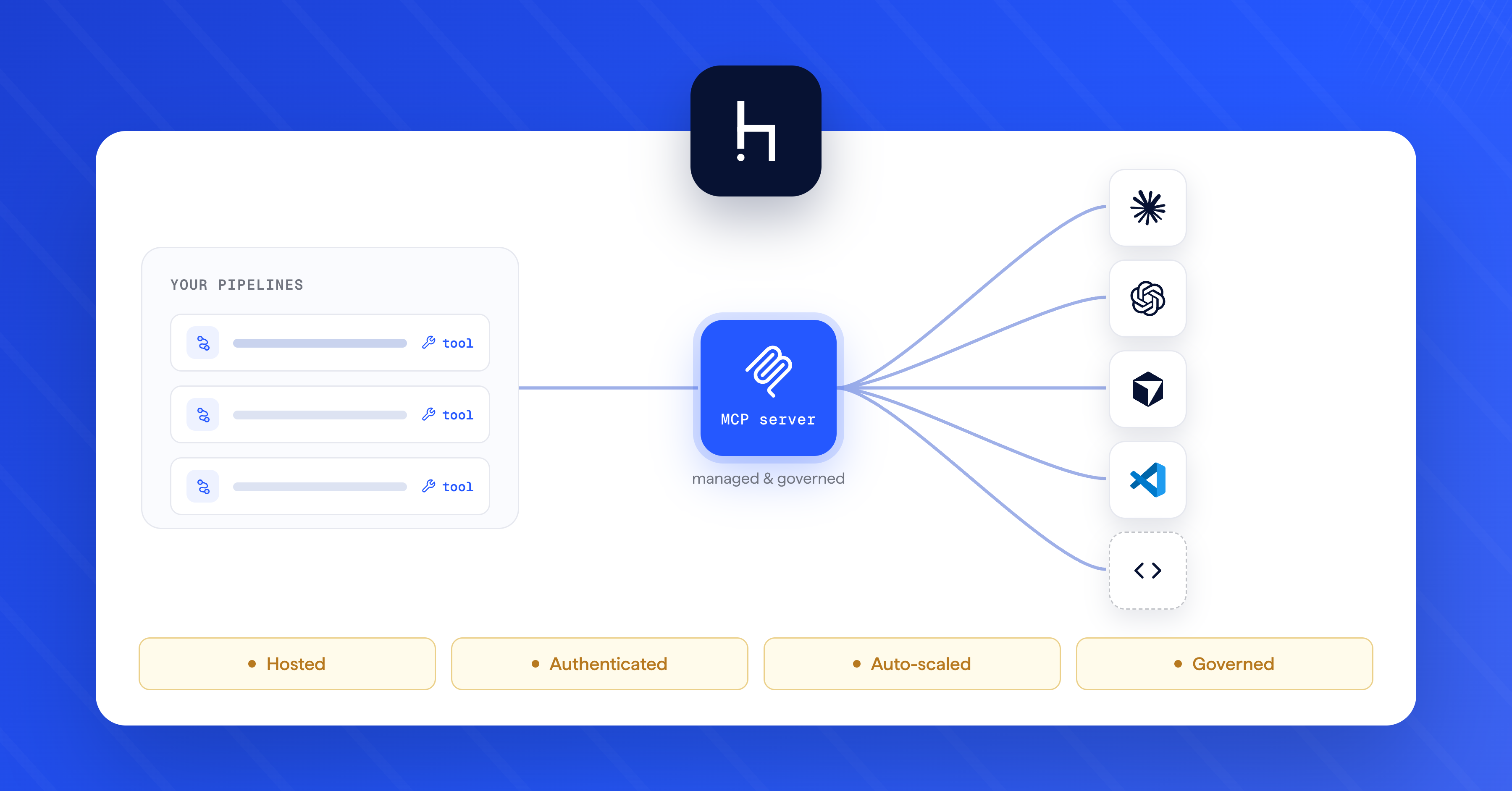
At deepset, we've been hard at work building an AI trust layer for our users to assess the quality and error sources of their generative AI products in our LLM platform. As a result, pipelines built with Haystack Enterprise Platform (formerly known as deepset AI Platform) are observable and transparent, adding a much-needed layer of visibility into the inner workings of LLMs. In this article, we're announcing the addition of the powerful Groundedness metric in the platform, which tracks the degree to which the answer from a retrieval augmented generation (RAG) system is based on the underlying documents.
Hallucinations: a big risk for LLM adoption
For LLMs to be used in real-world applications, safety is paramount. Hallucinations are unacceptable in live production systems, especially in highly sensitive areas such as aircraft technical documentation, where a hallucinated response could be life-threatening. Likewise, a user-facing system that hallucinates will quickly erode clients' trust in your application.
The RAG method of embedding documents from your database into the LLM prompt can improve the security and reliability of the application's output. In addition, a well-designed and tested prompt can significantly improve system performance. However, RAG pipelines can still produce inaccurate results when presented with queries about entities or events that do not exist in your database, or when faced with complex queries. Even so, metrics that can semantically quantify the truthfulness of an LLM's output have been few and far between.
Groundedness: Substantiated answers and how to quantify them
Groundedness describes the degree to which an answer generated by a RAG pipeline is supported by the retrieved documents. Also known as faithfulness, it is the opposite of hallucination. The whole idea behind the RAG setup is to ground an LLM's answers not in its own learned knowledge of the world, but in the database we provide it with. Today, any organization can embed an LLM through an API, but it's the data that's unique to your organization that makes it stand out. That's why you'll want to use semantically aware metrics that can evaluate how well the LLM adheres to your knowledge base.
Through a specialized language model, the Haystack Enterprise Platform now calculates a Groundedness Score for each response generated by a RAG pipeline, which quantifies the degree to which the LLM's answers are 'grounded' in the retrieved documents. A new interface allows you to track the metric over time:

The Groundedness Observability Dashboard shows you the pipeline's Groundedness metric within an adjustable time range (from one to 60 days), including the number of queries it's based on. In addition to this granular evaluation, you also have a tag that tells you at a glance how well your RAG pipeline is performing overall (the pipeline in our example is classified as "Poor," with a Groundedness Score of 0.64).
Having access to a quantifiable score of your RAG pipeline's output gives you the basis for improving it in several ways. Namely, you can:
- Compare the groundedness of different models when selecting an LLM.
- Improve your prompt with the Prompt Explorer and Groundedness Score metric.
- Optimize your retrieval setup.
While the first two points, LLM selection and prompt tuning, are fairly straightforward applications of the Groundedness Score, the last point deserves a closer look. As we'll see, an optimized retrieval step will not only improve the overall quality of your RAG pipeline's output, but often reduce costs as well.
Using groundedness to optimize retrieval
The documents that your retrieval step returns are typically ordered so that the most relevant document is first and the least relevant document is last. (You can improve that order by reranking the documents.) Regardless of the specific setup of your retrieval, the order of the documents is preserved when they're passed to the LLM. Combined with the Groundedness metric, this property can easily be used to evaluate and improve your retrieval.
In addition to measuring the quality of an LLM's output, our new Groundedness Observability feature also keeps track of which position of documents was most frequently used to ground an answer statement. Ideally, we would like the first document to be the most used, followed by the second, and so on. Let’s look at two different scenarios and their implications.
Scenario 1: Cutting LLM costs by 40 %
Powerful LLMs are expensive: You pay not only for the answers an LLM generates for you, but also for the data you feed it. To save money, our Groundedness Observability Dashboard can eliminate unnecessary and costly data entry by identifying underused documents. This is what the evaluation results look like when your retrieval works so well that your LLM actually uses the top documents most of the time:

In the above screenshot, we started by feeding the LLM ten retrieved documents. However, the Groundedness metric told us that documents in positions 7 through 10 are used in only 5% of the answers. By limiting the number of retrieved documents to 6, we’ve just saved 40% in LLM costs.
Scenario 2: Improve ranking of inefficiently ordered documents
As we said earlier, we want the positions of retrieved documents to reflect their respective relevance to the query. But what if, while evaluating your RAG pipeline with the Groundedness metric, you find that it is using lower-ranked documents as often (or even more often) as higher-ranked documents to inform its answers? That probably means something is wrong with the retrieval – plus, it's more likely that valuable documents are not being retrieved at all.

Fortunately, there are many ways to improve your retrieval setup, either by adding one or more rankers, combining different retrieval methods, or even fine-tuning your retriever. Because the models used for ranking and retrieval are small and open source, all of this can be done locally and at low cost – but with high impact.
Groundedness at a granular level: Source document references
The ability to track the Groundedness metric over time is incredibly valuable for organizations looking to monitor and evaluate a RAG pipeline that's deployed in production. But in its current form, it's not very useful for individual users who want to verify the answers they receive from a system. Our Reference Predictor changes all that: designed as a component that can be added to any RAG pipeline, it breaks down the pipeline's responses into individual statements and annotates them with academic-style citations. Unlike traditional referencing, which is done by the LLM itself, our method works reliably across all types of LLMs.

Users can then click on the references to verify an answer for themselves, or if they want to learn more about the document in context. Providing an easy way to fact-check the system's answers in such a granular way empowers your users and improves confidence in your product. To see the Reference Predictor in action, read our blog post about a RAG-powered documentation assistant in production.
Building secure and powerful applications with LLMs
At deepset, it’s long been our mission to bring the power of language models to all text-based applications. It’s been exciting to see the recent enthusiasm in the enterprise for experimenting with generative AI in customer-facing products. However, building with LLMs should not stop at experimentation. We’re certain: 2024 will be the year of widespread LLM adoption in production. That's why, now more than ever, we need robust semantic metrics to evaluate the various components of LLM-powered pipelines.
More and more global enterprises are choosing Haystack Enterprise Platform, for its maturity and ease of use. Our ever-expanding AI trust layer pioneers new levels of LLM reliability with features such as the Groundedness metric and the accompanying dashboard, reference prediction, and our popular prompt explorer. The platform is ready to take your product from conception to production and beyond, while ensuring its compliance, security, and transparency.
Curious about building AI Apps and Agents?

Table of Contents