GermanQuAD and GermanDPR
Datasets, models and learnings to advance question answering and passage retrieval for non-English search systems

GermanQuAD
Welcome to the home of GermanQuAD and GermanDPR — the latest in our hand-annotated question answering and passage retrieval datasets!
This complimentary pair was designed to take the German neural search to the next level, but also to share our learnings and inspire others to create similar assets for other languages and domains.
Read below to dive into the details of the creation, have a look at samples of the dataset or just "consume" our ready-to-use retriever and reader models.
Question Answering Dataset: GermanQuAD
In order to raise the bar for non-English QA, we are releasing a high-quality, human-labeled German QA dataset consisting of 13,722 questions, including a three-way annotated test set.
The creation of GermanQuAD was inspired by the insights from the existing datasets, as well as our own labeling experience from several industry projects.
We combine the strengths of SQuAD, such as high out-of-domain performance, with self-sufficient questions that contain all the relevant information for open-domain QA as in the NaturalQuestions dataset.
Our training and test datasets do not overlap like other popular datasets and include complex questions that cannot be answered with a single entity or only a few words.
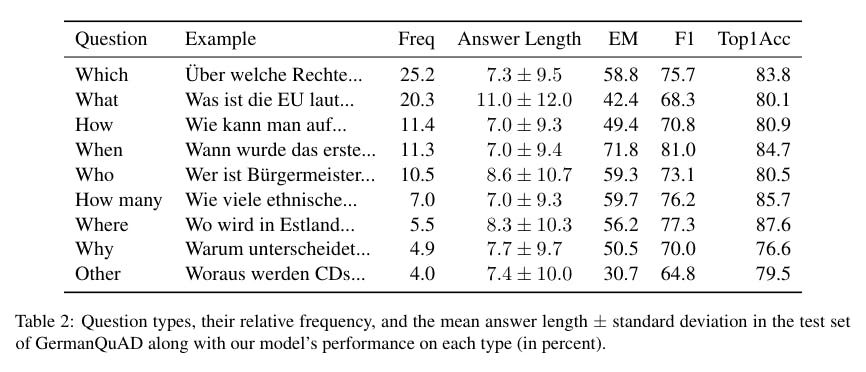
Passage Retrieval Dataset: GermanDPR
While Question Answering (QA) plays an important role in modern search pipelines, there's usually also no way around a high-performing document retriever — either to enable open-domain QA on large document bases or as a standalone function for document search.
We took GermanQuAD as a starting point and added hard negatives from a dump of the full German Wikipedia, following the approach of the DPR authors (Karpukhin et al., 2020). The format of the dataset also resembles the one of DPR. GermanDPR comprises 9,275 question/answer pairs in the training set and 1,025 pairs in the test set. For each pair, there are one positive context and three hard negative contexts.
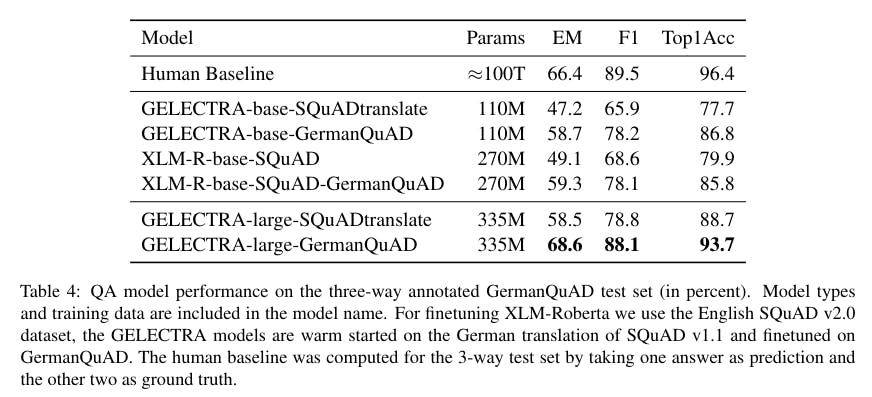
Base Models
We provide several models trained on our datasets as a baseline. You can find more details about their training and evaluation in the paper.
Interested in QA and neural search?
If you have any questions, trained new models on the datasets or just want to stay up-to-date on QA & semantic search, reach out to us or follow us on Twitter!
GermanQuAD
GermanQuAD stems from the insights on the existing datasets and our labeling experience of working with enterprise customers. We combine the strengths of SQuAD with self-sufficient questions that contain all the relevant information for open-domain QA. This is a human-labeled dataset of 13,722 questions and answers.