Semantic FAQ Search with Haystack
Leverage the power of the Transformer models to help users find answers in FAQs.
01.09.21

Frequently Asked Questions (FAQs) are a great initial reference for potential customers looking for help with your product. FAQs should be carefully drafted and present solutions to the most common issues a user can encounter.
However, most search implementations for FAQs are keyword-based: They require users to hit the exact words used in your FAQ database. Wouldn’t it be nice if search systems for FAQ could better understand the intent behind a query? That’s what we’ll cover in this article. Keep reading if you want to learn more about adding semantics to your FAQ search system.
Why FAQ Search Is Useful
A database of well-curated FAQs can enhance the user’s self-help experience, while minimizing the burden on customer support. If your FAQs are helpful and detailed, they can make a big difference in terms of customer satisfaction. But the larger your FAQ collection, the more concerned you should be with ensuring that it’s easily searchable for your users.
A typical naive FAQ search system requires the user to formulate a query in the exact (or near exact) terms used in the question you’ve addressed. That’s not very user-friendly — what if a user is looking for information on how to deal with “lost login credentials”, but your FAQs only offer an answer to “How to reset my password”?
In that case, keyword-matching won’t take you far. Enter Transformer-based language models like BERT, RoBERTa and MiniLM. They are able to go beyond the literal and grasp the meaning behind a given query (i.e. the semantics). As you might imagine, such models have plenty of applications, with question answering among them — and it’s the one we at Haystack are most excited about!
Semantic FAQ Search Using Language Models
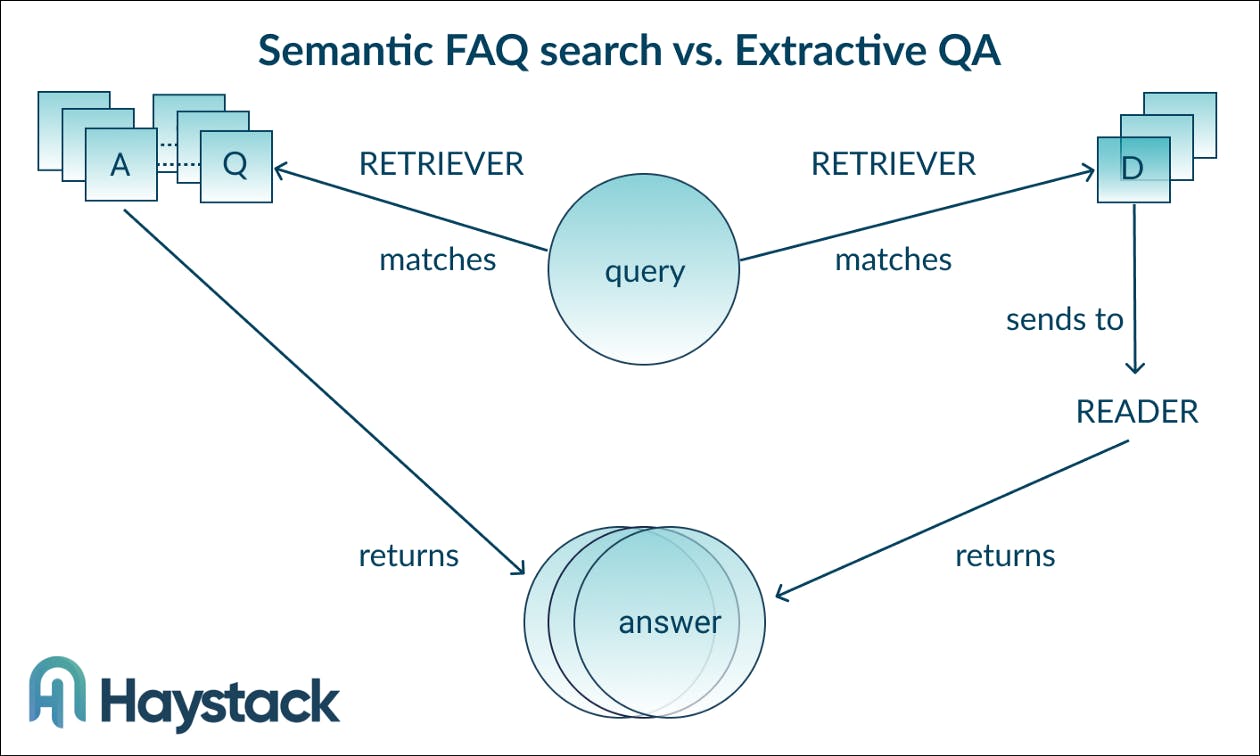
To understand how search systems work, let’s briefly look at the most common application of question answering: In extractive QA, a retriever compares a given query to the documents in a database, and returns the passages with the highest similarity. The retriever can be based on keywords or on a more complex, “dense” representation. Dense methods use language models to abstract away from the lexical level and introduce semantics into the system.
In turn, an FAQ search system compares short strings (the queries) to similarly short strings (the question portion of an FAQ question answer pair). To that end, the dense retrieval model Sentence-transformers represents our FAQ questions as vectors in a high-dimensional embedding space. Our retriever then finds the vectors closest to it, using cosine distance as a similarity measure.
While the system compares our queries to the questions (or rather, their embeddings) in the database, we want it to return the answer associated with that question — and of course not the question itself. The above requires a specific setup of our document store, which we’ll go through in our practical example.
Example: Building a Semantic FAQ Search System in Haystack
In this example, we’ll be building an FAQ pipeline on top of a small dataset of FAQs about chocolate. First, we initialize the document store:
from haystack.document_store.elasticsearch import ElasticsearchDocumentStore
document_store = ElasticsearchDocumentStore(host="localhost",
username="",
password="",
index="document",
embedding_field='embedding',
embedding_dim=384,
excluded_meta_data=['embedding'],
similarity='cosine')In the document store, we selected ‘embedding’ as the field where the sentence embeddings of our frequently asked questions will be stored. In the field excluded_meta_data, we specify that the vectors should not be included in answers. After all, an embedding is just a long list of numbers that only a computer can make sense of.
To work with a sentence embedder, we’ll need to use the EmbeddingRetriever. We load the MiniLM language model from the Hugging Face’s Model Hub and set top_k (the number of documents selected by the retriever) to 1. Accordingly, our system will return only the top question-answer pair.
from haystack.retriever.dense import EmbeddingRetriever
retriever = EmbeddingRetriever(document_store=document_store, embedding_model='sentence-transformers/all-MiniLM-L6-v2', use_gpu=True, top_k=1)We read our dataset in with the pandas library and extract the questions as a list:
import pandas as pd
df = pd.read_csv('chocolate_faq.csv')
questions = list(df.question.values)In the next step, we’ll let MiniLM turn the questions into sentence embedding vectors. These vectors are stored in our pandas dataframe under the column name ‘embedding’:
df['embedding'] = retriever.embed_queries(texts=questions)
df = df.rename(columns={"question": "text"})Finally, we turn our dataframe into a list of dictionaries and write them to the document store.
dicts = df.to_dict(orient="records")
document_store.write_documents(dicts)How do our documents look? Let’s check:
dicts[0]
>>> {'text': 'What is chocolate? Where does it come from?', 'answer': "Chocolate is a food made from the seeds of a tropical tree called the cacao. These trees flourish in warm, moist climates. Most of the world's cacao beans come from West Africa, where Ghana, the Ivory Coast and Nigeria are the largest producers. Because of a spelling error, probably by English traders long ago, these beans became known as cocoa beans.", 'embedding': array([-3.99257487e-01, 8.07830377e-01, 5.06629814e-01, -2.95400132e-02, ...Our dicts variable holds a list of dictionaries, each containing a question-answer pair (under ‘text’ and ‘answer’, respectively) and a long vector that’s a sentence embedding of the question. As we specified when setting up the document store, our retriever only searches the ‘embedding’ field. The rest of our system’s behavior is handled by the ready-made FAQPipeline, which we initialize next:
from haystack.pipeline import FAQPipeline
pipeline = FAQPipeline(retriever=retriever)Our pipeline is ready! Let’s try it out by asking this burning question:
reply = pipeline.run(query="Is chocolate bad for the skin?")pipeline.run() returns a dictionary containing a list of answers, which again are stored in dictionary format. Since we set the top_k value to 1, our list holds only one item. Let’s see what answer our system thinks best addresses our question:
reply['answers'][0]['answer']
>>> 'This is another myth about chocolate. While some people might be allergic to chocolate, or some of its ingredients, the belief that chocolate causes acne universally has been disproven by doctors for some time.'This looks solid. But which FAQ question was our query matched to? We find it under “query”:
reply['answers'][0]['query']
>>> "Doesn't chocolate cause acne?"As you can see, the original question did not explicitly refer to “skin.” However, thanks to the sentence embedding, the system picked up on the similarity of the two questions in context. We’re pretty happy with this result! Let’s try another example:
reply = pipeline.run(query="Can I feed my rat chocolate?")
reply['answers'][0]['answer']
>>> 'Unequivocally, no. The theobromine in chocolate that stimulates the cardiac and nervous systems is too much for dogs, especially smaller pups. A chocolate bar is poisonous to dogs and can even be lethal. The same holds true for cats, and other household pets.'Good to know! But how about the original question — did it make any reference to rats?
reply['answers'][0]['query']
>>> 'Can I give chocolate to my dog (cat, bird, other pet)?'Again, the MiniLM language model allowed our system to grasp the semantic similarity between dogs, cats, and pet rats.
Semantic FAQ Search in Production
Once you’ve set up your FAQ pipeline, you probably want to bring it to production. To guide you through the process, have a look at our tutorial on deploying a REST API with Haystack.
If you have more textual data about your product in addition to the FAQs — for example, a general documentation page — you might want to build a custom pipeline that combines semantic FAQ search with an extractive QA system. For instance, you could let the system fall back on extractive QA if the confidence scores returned by your FAQ search fall below a threshold.
Enhance Customer Experience with Haystack’s Semantic FAQ Search
Want to implement your own Semantic FAQ pipeline?
Check out our GitHub repository — and if you like what you see, feel free to give us a star :)

