Configuring Haystack Pipelines with YAML
Configuring Haystack pipelines through YAML makes it easier to set up a question answering system.
10.09.21
What is YAML?
YAML (YAML ain’t markup language) is a serialization format that you can use to create configuration files. These files provide your program with the information it needs to run, based on your desired setup or environment. This eliminates the need of hardcoding such information into the program itself.
Configuring your pipelines through YAML allows you to make quick tweaks to your system, manage your system’s parameters in production, and run distributed execution.
- YAML is particularly useful for conducting experiments. You can use YAML to adjust your entire pipeline from within the configuration file instead of changing parameters and components directly in the source code. This allows you to easily keep track of your experiments since you only have to record the changes in the configuration file.
- When running Haystack behind a REST API, you’ll need to define your pipeline of choice in the API’s pipelines.yaml file.
- You’ll need to use YAML if you want to parallelize your pipeline and allow distributed execution with the RAY API. You can use RAY to run each pipeline component on a different machine. For example, rather than scaling an entire server due to one resource-intensive component (typically the Reader), you can run this component on an outside server that you’d specify inside the YAML configuration file.
Defining Pipelines with YAML
You can use YAML to define the full extent of a Haystack-based neural search by creating a pipeline configuration file (e.g., a question answering, or semantic search system).
At the top level of a YAML file’s hierarchical structure, we define our system’s main building blocks:
- “Components,” for defining Haystack components such as Readers and Retrievers; and,
- “Pipelines,” for defining the Haystack Pipelines that chain the components together.
Each object in a YAML configuration file contains attributes, expressed as key and value pairs placed after an indentation. To change an object’s attribute, simply modify the corresponding attribute within the enclosing scope of the object in question.
Components
Say you wanted to create a Reader that uses the MiniLM model. You could do this by adding the following lines to your YAML configuration file:
...
components:
- name: MyReader
type: FARMReader
params:
model_name_or_path: deepset/minilm-uncased-squad2
pipelines:
..The configuration above is equal to the following Python code:
MyReader = FARMReader(model_name_or_path="deepset/minilm-uncased-squad2")Pipelines
Now, what if you wanted to create a Pipeline that connects your Retriever and Reader? You could do so by adding the following lines to your pipelines.yaml file:
...
pipelines:
- name: query
nodes:
- inputs:
- Query
name: MyRetriever
- inputs:
- MyRetriever
name: MyReader
type: QueryThis configuration is equivalent to the Python code below.
pipeline = Pipeline()
pipeline.add_node(component=MyRetriever, name="MyRetriever", inputs=["Query"])
pipeline.add_node(component=MyReader, name='MyReader', inputs=['MyRetriever'])Saving and Loading YAML Files
Defining your pipelines in YAML is especially useful as you move between experimentation and production environments. YAML files allow you to easily import your pipeline file into your notebook or an IDE, make adjustments, and export the configuration into your production environment. Let’s see how below.
We’ll load a predefined pipeline by importing the pipeline’s YAML configuration file. We do so by calling the Pipeline.load_from_yaml() method and providing it the configuration file’s location.
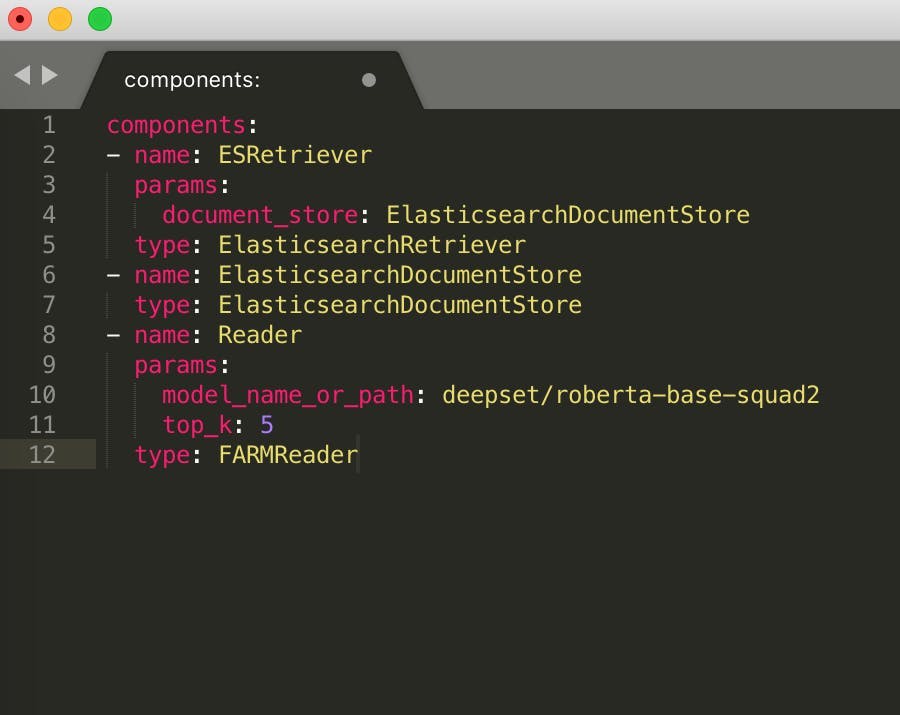
pipeline = Pipeline.load_from_yaml("haystack/rest_api/pipeline/pipelines.yaml")Here’s how our YAML configuration file looks:
components:
- name: ESRetriever
params:
document_store: ElasticsearchDocumentStore
type: ElasticsearchRetriever
- name: ElasticsearchDocumentStore
type: ElasticsearchDocumentStore
- name: Reader
params:
model_name_or_path: deepset/roberta-base-squad2
top_k: 5
type: FARMReader
pipelines:
- name: query
nodes:
- inputs:
- Query
name: ESRetriever
- inputs:
- ESRetriever
name: Reader
type: Query
version: '0.8'Say that we wanted to insert a Translator node at the end of our pipeline. We could add the component to the graph and pipe the Reader’s output into it:
translator = TransformersTranslator(model_name_or_path="Helsinki-NLP/opus-mt-en-de")
pipeline.add_node(component=translator, name="Translator", inputs=["Reader"])Now, we can export the modified pipeline’s configuration by calling the Pipeline.save_to_yaml() method. This will create a pipelines.yaml file in the directory specified in the method call.
pipeline.save_to_yaml(path="haystack/rest_api/pipeline/pipelines.yaml")Let’s check our new configuration file to verify that the changes were indeed saved:
components:
- name: ESRetriever
params:
document_store: ElasticsearchDocumentStore
type: ElasticsearchRetriever
- name: ElasticsearchDocumentStore
params: {}
type: ElasticsearchDocumentStore
- name: Reader
params:
model_name_or_path: deepset/roberta-base-squad2
top_k: 5
type: FARMReader
- name: Translator
params:
model_name_or_path: Helsinki-NLP/opus-mt-en-de
type: TransformersTranslator
pipelines:
- name: query
nodes:
- inputs:
- Query
name: ESRetriever
- inputs:
- ESRetriever
name: Reader
- inputs:
- Reader
name: Translator
type: Query
version: '0.8'The Translator node was successfully added to the end of the file.
Example: Defining a Haystack pipeline in YAML and deploying it with a REST API
Let’s look at an example of a Haystack pipeline YAML definition based on rest_api/pipeline/pipelines.yaml.
We start by defining our QA system’s components. We’ll create an extractive-QA pipeline, for which we’ll need two components: a Reader for finding answers to queries, and a Retriever for filtering the inputs to the Reader. The Reader needs to reference a document store, so we’ll also define a third component, a DocumentStore.
Here’s how the resulting YAML definitions look:
version: '0.7'
components:
- name: ElasticsearchDocumentStore
type: ElasticsearchDocumentStore
params:
host: localhost
- name: ESRetriever
type: ElasticsearchRetriever
params:
document_store: ElasticsearchDocumentStore
top_k: 10
- name: Reader
type: FARMReader
params:
model_name_or_path: deepset/roberta-base-squad2
top_k: 5After defining the individual components, we can place them into a pipeline. Our pipeline will receive a query from the input, pass it on to the Retriever, and then to the Reader.
We’ll add the following definitions to our file and save it at rest_api/pipeline/pipelines.yaml:
pipelines:
- name: query
type: Query
nodes:
- name: ESRetriever
inputs: [Query]
- name: Reader
inputs: [ESRetriever]Now that we’ve defined our pipeline, we’ll set up a simple Haystack API. We’ll use the default setup provided in the docker-compose.yml file. We’ll navigate to the directory with Haystack’s installation and start the API container by running the following commands:
docker-compose pull
docker-compose upRunning the above commands starts the Docker images required to run the HTTP API server, a data store based on Game of Thrones texts, and a web user interface. Note that the Haystack API container defaults to the pipeline defined in the rest_api/pipeline/pipelines.yaml file. If you want to direct the API container to use a YAML file at a different location, you can set the PIPELINE_YAML_PATH environment variable to point to a different location. In a docker-compose.yml file, you can set an environment variable like so:
services:
haystack-api:
...
environment:
- PIPELINE_YAML_PATH=newpath/pipelines.yamlJust like that, we’ve started a Haystack API with a pipeline defined in the pipelines.yaml file. To verify that our pipeline works, we can ask it a question:
$ curl --request POST --url 'http://127.0.0.1:8000/query' -H "Content-Type: application/json" --data '{"query": "Which season of Game of Thrones has the episode with the highest rating?"}'And here’s the output:
{
"query": "Which season of Game of Thrones has highest ratings?",
"answers": [
{
"answer": "seventh",
"question": null,
"score": 0.9208154082298279,
"probability": null,
"context": "s the highest rated episode of the series to that point, surpassing the seventh season premiere, which previously held the record. The episode also ac",
...
}
]
}We hope you find the examples above helpful. For more information on building a Haystack REST API, check out our REST API documentation and the REST API tutorial.
Last but not least, you are most welcome to join our Haystack community here on Discord and on GitHub Discussions as well. We always really appreciate a star to the Haystack repository too!

