Beyond ‘Vanilla’ Question Answering
Sentiment classification, summarization and even natural language generation can all be part of your question answering system
17.09.21

With Haystack, you can set up a fully functional question answering system (QA) in under 30 minutes. But did you know that you could add nodes to your pipeline to leverage all kinds of Transformer-based language models? For example, you could include a module for sentiment analysis, or one that summarizes the pipeline output.
In this post, we show you how to benefit from a wide range of pre-trained Transformer models. As always, the goal is to boost both your pipeline efficiency and the quality of its output. Specifically, we’ll be looking into three different nodes: the Summarizer, the Classification node, and the Generator. Let’s jump right in!
Creating Metadata with the Classification Node
The Classification node is relatively new and we’re particularly excited about it. It accepts a machine learning model that’s been pre-trained on any kind of classification task: Be it sentiment analysis, named entity recognition or hate speech detection.
It complements our well-established Query classifier. However, rather than classifying queries, this node classifies answer candidates selected by the Retriever.
Recall that the Query classifier has two outgoing edges and routes queries to one of the two, depending on the assigned label. By contrast, the Classification node has only one outgoing edge. It predicts labels for incoming documents and adds them to the documents’ metadata.
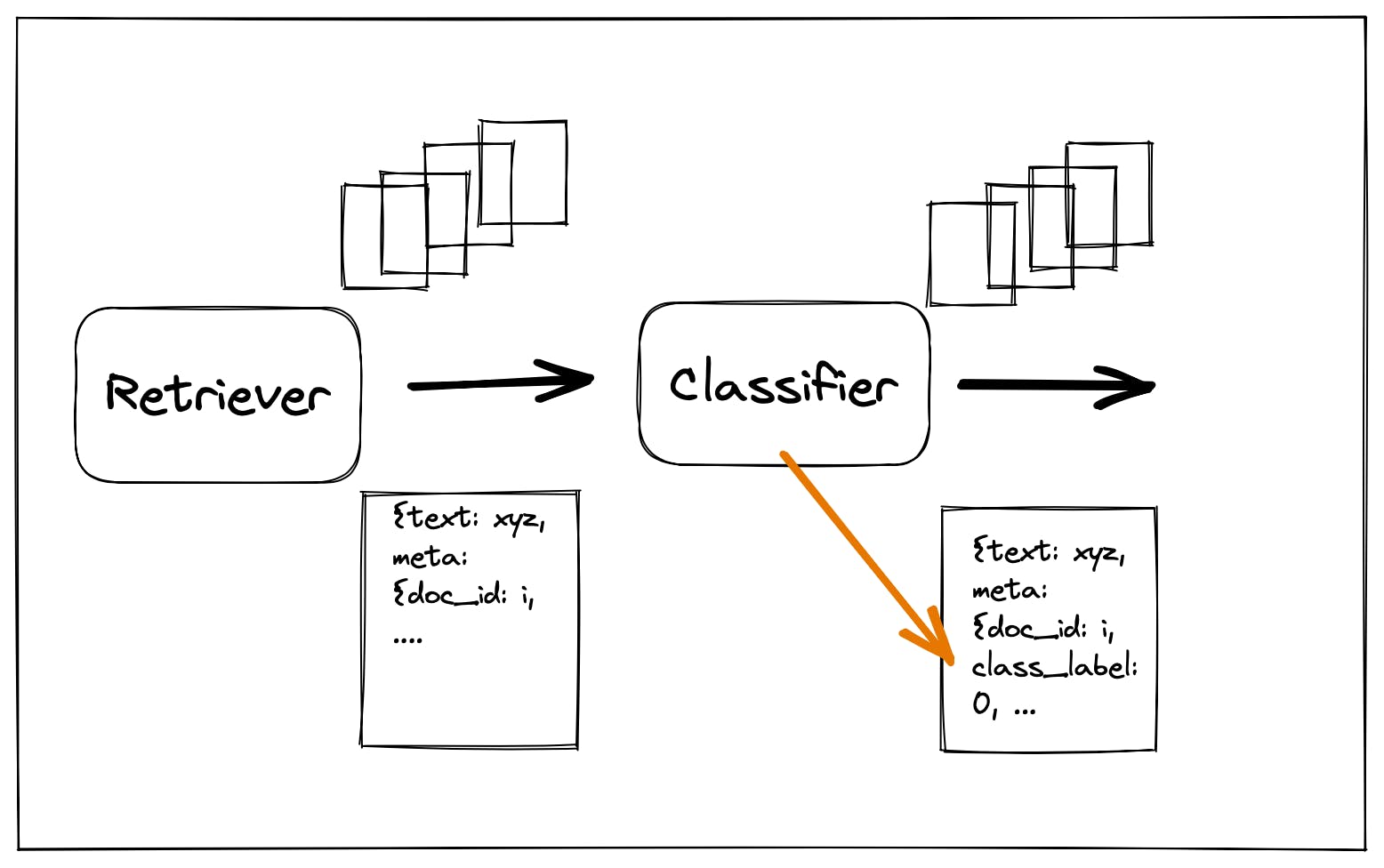
We’ve previously shown how you can use metadata to add a filter to your pipeline and improve its speed and accuracy. But annotating large amounts of data is expensive, and we may not have the exact metadata for our filter of choice. In such cases, the Classification node allows us to integrate a machine learning model to classify our documents and generate our own metadata — like a label that tells us whether a document is positive, negative or neutral in tone.
The Classifier in Action
To use the Classifier, we need to install the newest version of Haystack from master:
pip install git+https://github.com/deepset-ai/haystack.gitIn this example, we’ll be working with a Classifier for sentiment analysis — the task of labeling a given text’s sentiment or attitude. Is it positive or negative, or somewhere in between? We choose a pre-trained, binary sentiment classifier from the Hugging Face Model Hub and pass its name to FARMClassifier:
from haystack.classifier import FARMClassifier
classifier_model = 'textattack/bert-base-uncased-imdb'
classifier = FARMClassifier(model_name_or_path=classifier_model)Next, we initialize the pipeline as usual, this time adding the Classifier node right after the Retriever node:
pipeline = Pipeline()
pipeline.add_node(component=retriever, name="Retriever", inputs=["Query"])
pipeline.add_node(component=classifier, name='Classifier', inputs=['Retriever'])For the practical examples in this post, we’ll be working with the “Toys and Games” slice from the large Amazon Reviews dataset. We’ve read the reviews into the document store, keeping the item IDs as metadata. For the next search, we only want to look at reviews of this slurpee maker, so we pass a filter to our pipeline:
filter = {'item_id': ['B007X9DRWO']}
result = pipeline.run(query='How is the quality of this product?', filters=filter, top_k_retriever=30)The pipeline returns the result to our query as a nested dictionary. Under the ‘documents’ key, we find the answer documents, each having received a label from the classification node: ‘LABEL_1’ for a positive sentiment, or ‘LABEL_0’ for negative. Let’s look at the first positively classified review:
documents = result['documents']
[doc.text for doc in documents if doc.meta['classification']['label'] == 'LABEL_1'][0]
>>> "Children will love this toy. As we all know, kids (and a good number of adults as well, I might add) love Slurpees. And this product, which enables the children to create their own drink, is a sure winner. Cleanup isn't much, either, so this Slurpee Maker comes recommended - would definitely make a nice gift."And how about the first negative review?
[doc.text for doc in documents if doc.meta['classification']['label'] == 'LABEL_0'][0]
>>> 'I wish I could rate this higher because I love Slurpee brand. The plastic this product is made from is so cheap, it breaks easily and since it\'s for kids - described as a "toy" it should be more durable. They made it completely disassemble, which is great for cleaning, but makes it a mess to wash, dry, and store, besides the fact that when you are moving it or trying to use it it keeps falling apart. You must have salt to make the contraption work and kids get tired of turning the pump to make it work. The'For the sake of this example, we’ve ignored the fact that the Amazon Reviews data actually comes with a sentiment label attached. If you’re working with data that has no such information, adding a classification node to your pipeline can provide valuable insights into the nature of your results.
Trim Down Your Reading Time with the Summarizer
In some cases, we won’t find the best answer to a query in a single passage, but rather by aggregating several documents. This reality motivated us to create the Summarizer node. It uses a pre-trained model to create a summary of the documents returned by the Retriever.
The Summarizer in Action
To build a summarization system, we’ll combine a Retriever and a Summarizer in a pipeline. When initializing the Summarizer, we specify a minimum and maximum number of words per summary. Setting the generate_single_summary parameter to “True” gives us one summary of all the returned documents, while setting it to “False” creates one summary per document:
from haystack.summarizer import TransformersSummarizer
summarizer = TransformersSummarizer(model_name_or_path='t5-large', min_length=10, max_length=300, generate_single_summary=True)The ready-made SearchSummarizationPipeline class allows us to set up the entire pipeline in one line:
pipeline = SearchSummarizationPipeline(retriever=retriever, summarizer=summarizer)Let’s create a summary for this card game for kids. When working with the Summarizer, we’ll typically want to use keyword queries rather than natural language questions:
filter = {'item_id': ['B0039S7NO6']}
result = pipeline.run(query='preschooler suitability', filters=filter, top_k_retriever=5)This time, the ‘result’ dictionary is a list with one document. Let’s look at the summary we obtained for our query which we find under the ‘text’ key:
result['documents'][0].text
>>> "'this game is surprisingly fun, and entertains for quite a while. even my three-year-old plays almost as well as the rest of the family. the game is for all genders and ages 4+."To confirm that this result is indeed a newly generated summary of all of the documents retrieved in response to our query, let’s have a look at the answer candidates. They are stored in concatenated format as part of the metadata, under the ‘context’ key:
result['documents'][0].meta['context']
>>> "The best thing about this game is that even a 5 year old can play it and explain it to friends without adult supervision. Fun, quick and easy to pack. This is a fun game for a group of friends or just our kids (ages 6-10) and us! Easy to play and understand. I bought this game for my daughters (ages 3 & 5) for Christmas after reading several reviews. It's a simple game, you simply have to figure out which figures match on two game cards, but it's surprisingly fun, and entertains for quite a while. What I like about it is that even my three-year-old plays almost as well as the rest of the family. This is a great game (with multiple playing options), good for a quick five minutes, or playing variation after variation. My 4 year old enjoys the game, as do my husband and I. This game is for all genders and ages 4+. Great birthday gift to have waiting in the closet. Fun, simple, and inexpensive game for children of all ages. The younger kids (3-5) can play cooperatively and older kids 6+ can play more competitively. "Combining Ranker and Summarizer
The Summarizer is sensitive to the order of the documents it receives. That’s why adding a Ranker node to the pipeline can lead to better summaries. It sorts the documents returned by the Retriever according to their relevance to the query. Visit our documentation page to learn more about the Ranker.
Get Answers Written Just for You with the Generator
Transformer-based language models are already impressing us with their ability to interpret natural language. But it’s something else to see them create statements from scratch. With the AnswerGenerator node, you can add this capability to your question answering pipeline.
The Generator in Action
Unlike the other models mentioned in this article, the Generator only works in tandem with the dense passage retrieval (DPR) method. Make sure to initialize the DPR Retriever first, as it needs to be passed to both the Generator and the pipeline object:
from haystack.generator.transformers import RAGenerator
from haystack.pipeline import GenerativeQAPipeline
generator = RAGenerator(
model_name_or_path="facebook/rag-sequence-nq",
retriever=dpr_retriever,
top_k=1,
min_length=2)
pipeline = GenerativeQAPipeline(generator=generator, retriever=dpr_retriever)Because the review dataset is inherently opinion-based, we’ll ask our system a subjective question:
result = pipelines.run(query='What are the best party games for adults?', top_k_retriever=20)
result['answers'][0]['answer']
>>> "wit's & wagers & darts"Sounds like a fun evening! A closer look at the retrieved documents (which are too long to display here) reveals that all the reviews spelled “Wits & Wagers” correctly. The misspelling in the answer then confirms that, rather than simply extracting the game’s name from one of the documents, the node generated it from scratch.
If you’d like to read more on this topic, check out the following article on long-form question answering (LFQA) by Vladimir Blagojevic.
Even More NLP Magic
As we’ve seen, Haystack goes far beyond simple question answering systems. But there’s more: did you know that you could also use the Question Generator to generate questions from scratch? That comes in handy when creating new QA datasets! We’re preparing a full-length tutorial on this node, so stay tuned.
You could also add a multilingual aspect to your QA system. What if your database were in English, but you wanted your users to be able to ask questions in Arabic, French, or Hindi? No problem! Simply add a TranslationWrapper to your pipeline.
Explore Question Answering and More in Haystack
Want to learn more about what Haystack’s natural language processing tools can do for you?
Head over to our GitHub repository. If you like what you see, give us a star :)

